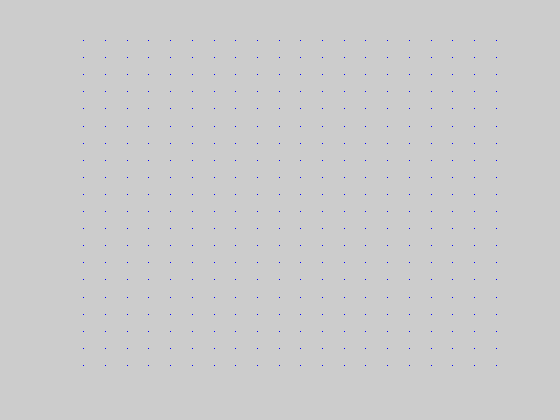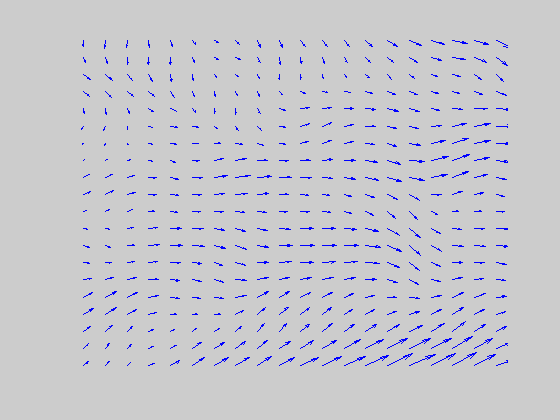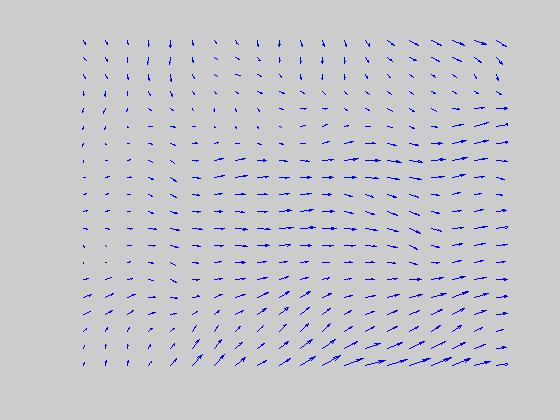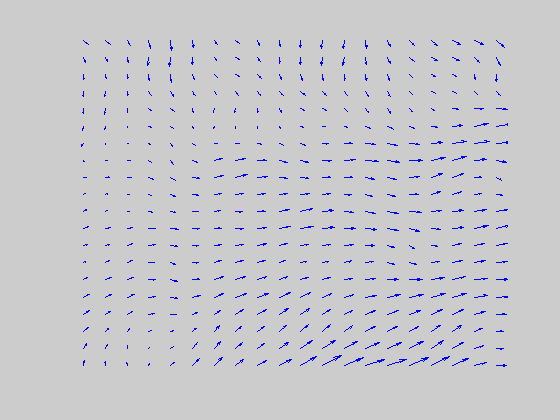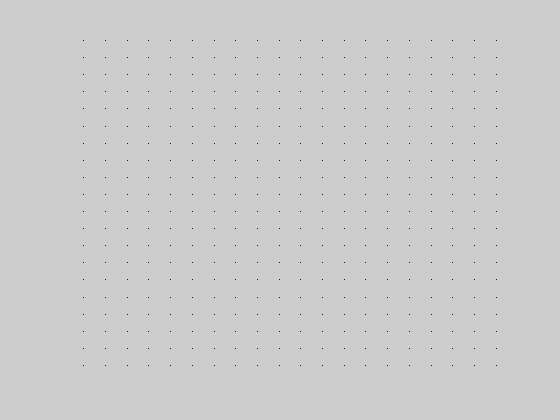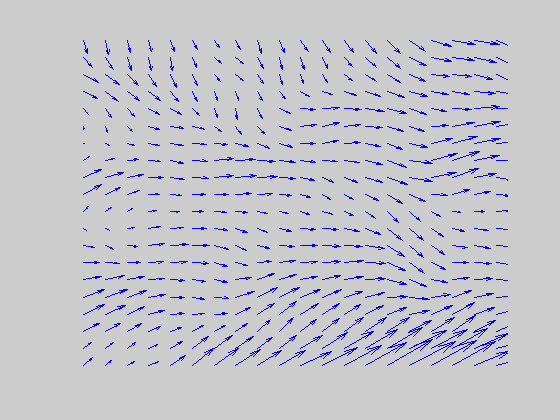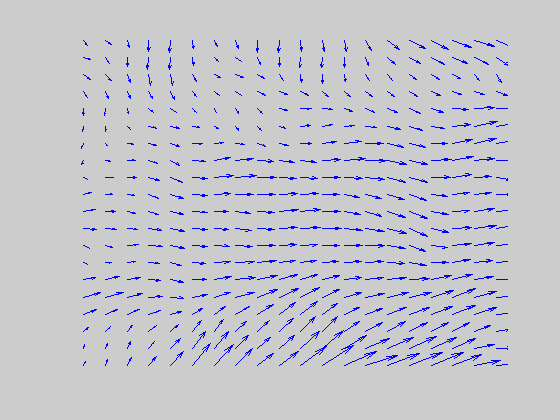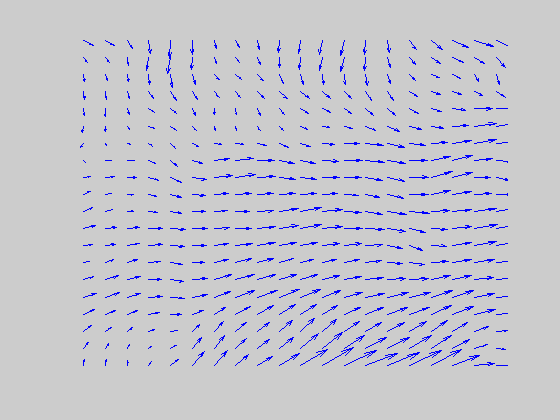INPUT
|
51.2% coherence (right direction) random dot motion stimulus presented at 60 Hz with 3 frame interleaving. (Each frame is 60 x 60.) |
|
|
|
||
NON-DIRECTIONAL TRANSIENT CELLS
|
Whenever a dot flashes at any location, a transient response is elicited there. For a luminance increment of 255 units, the model produces a response that lasts about 50 ms. (Each frame is 60 x 60. Grayscale intensity codes activity.) |
|
|
|
||
DIRECTIONAL TRANSIENT CELLS
|
Directional transient cells generate local directional signals between any two non-directional transients that occur with an appropriate spatio-temporal displacement. (Each frame corresponds to the central 20 x 20 locations. Each point in the frame can potentially have 8 equally spaced vectors emanating from it with magnitudes that are proportional to the responses of the corresponding cells.) |
|
|
|
||
DIRECTIONAL SHORT-RANGE FILTERS
|
Directional evidence is accumulated from any active directional transients that occur within the directionally selective receptive field of the short-range filter. Typically the signal direction will be amplified more than others. Note that a local directional grouping caused by signal dots is equivalent to a “feature tracking” (FT) signal. Apart from being few in number, these FT signals also have a short life span because a new set of signal dots are chosen every frame. (Each frame corresponds to the central 20 x 20 locations. Vector representation is used.) |
|
|
|
||
DIRECTIONAL LONG-RANGE FILTERS
|
The long-range filter pools local signals with the same directional preference over a larger spatial area, and participates in the motion capture process along with MST. (Left, for better visualization of real time MT responses, the 60 x 60 space is tessellated into 3 x 3 blocks and a directional population vector is computed for each block. Right, blue refers to the population average of the rightward pool of MT neurons and red to the leftward pool.) |
DIRECTIONAL LONG-RANGE FILTERS
|
|
|
||
DIRECTIONAL GROUPING NETWORK
|
In MST, all directions compete to determine a winner at each position. Enhanced “feature tracking” signals typically win this competition over “ambiguous” motion signals at their positions. Motion capture begins when model MST cells that encode the winning directions feed back to model MT cells via a top-down spatial filter, where they indirectly boost directionally consistent cell activities by suppressing inconsistent directional cells over the spatial region to which they project. The effectiveness of the motion capture process depends on input coherence and exposure duration. (Left, for better visualization of real time MST responses, the 60 x 60 space is tessellated into 3 x 3 blocks and a directional population vector is computed for each block. Right, blue refers to the population average of the rightward pool of MST neurons and red to the leftward pool.) |
DIRECTIONAL GROUPING NETWORK
|
|
|
||
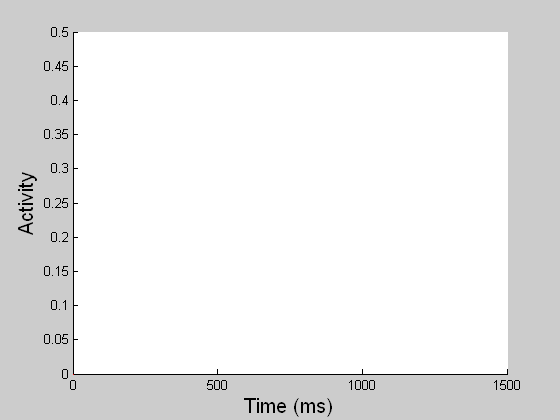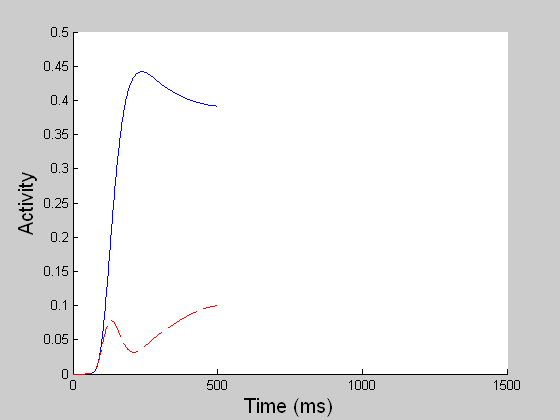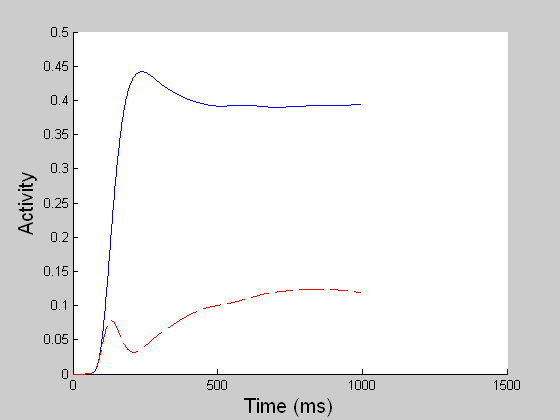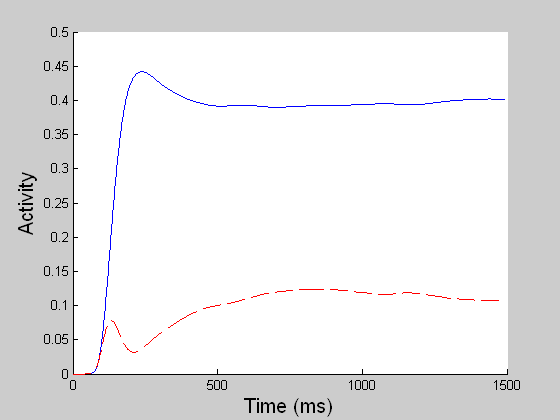
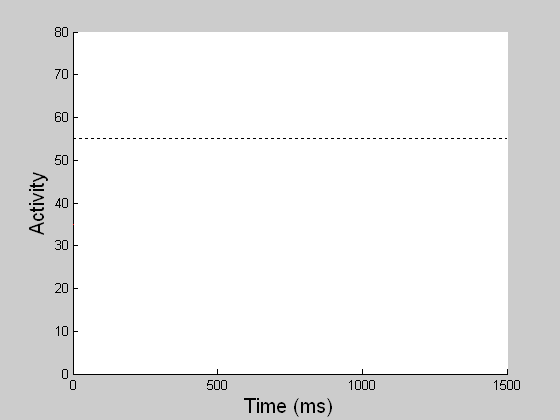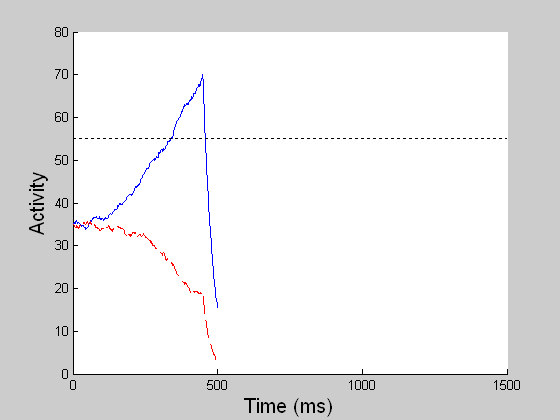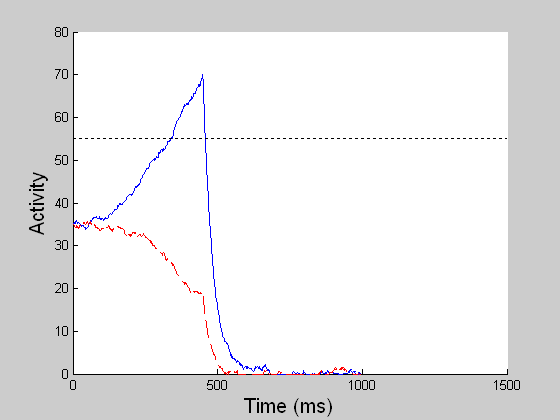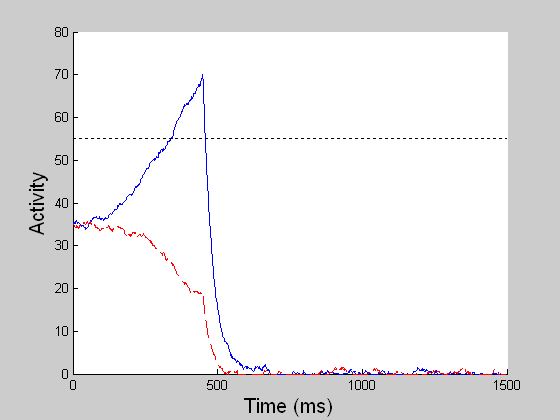
DECISION CELLS AND DECISION GATINGREACTION TIME TASK
|
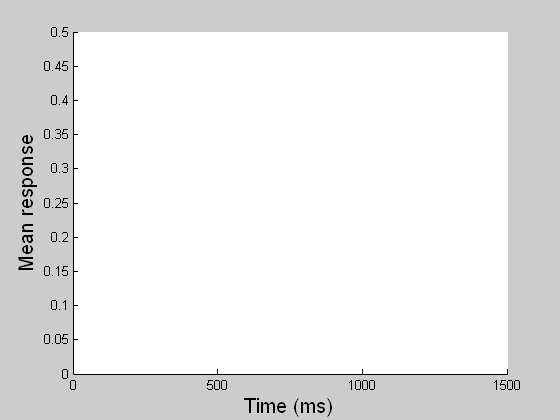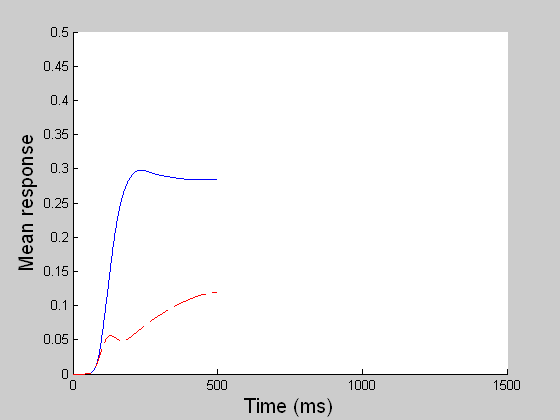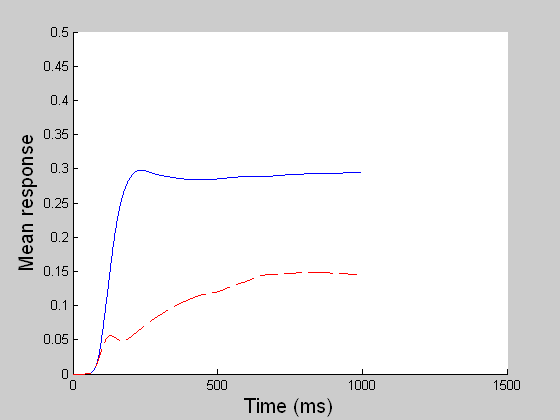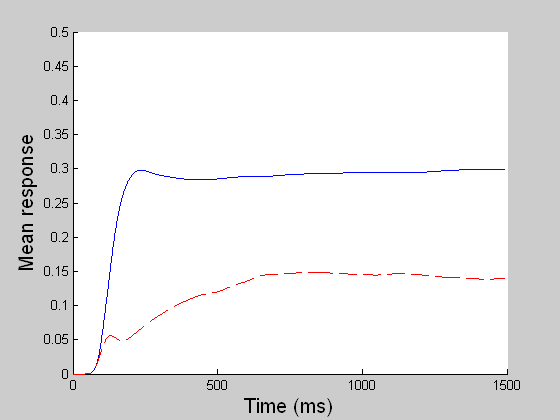
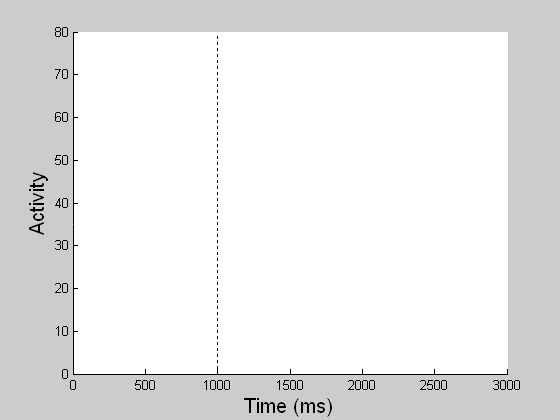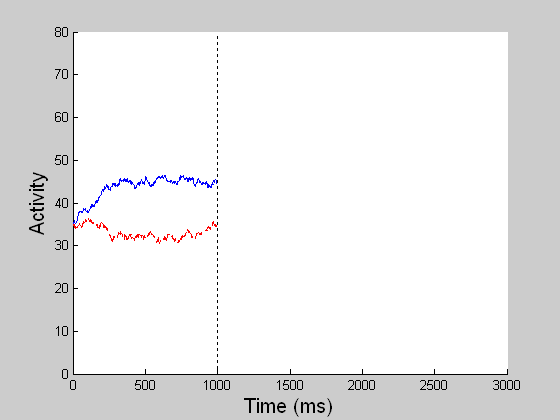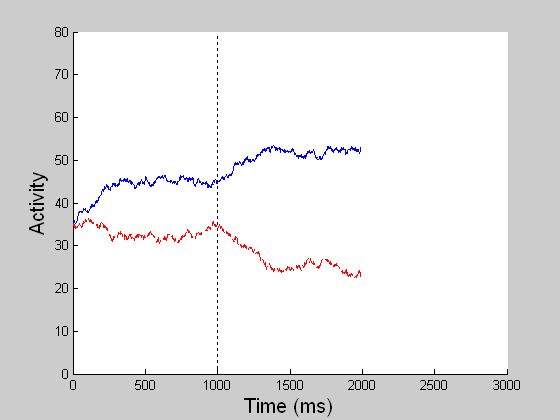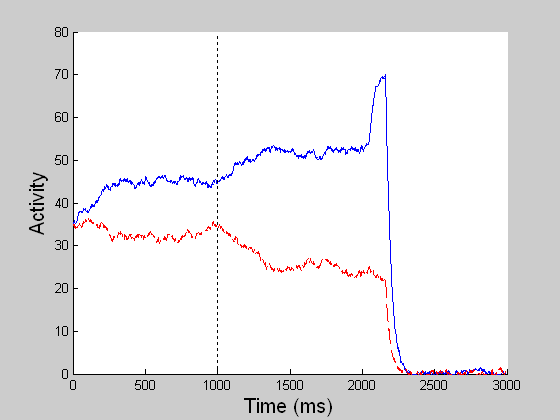
While model MT and MST compute the veridical global motion direction of the dots as much as possible, model LIP computes the stochastic perceptual decision by transforming the spatially distributed MST motion signals (sensory) into a saccadic eye movement (motor). In the reaction time (RT) task, a decision is reached when one of the competing LIP cells first reaches a threshold (55 units) and in the fixed duration (FD) task, a decision is made given all the evidence accumulated by the end of the viewing period (1 sec). The BG releases the gate for the chosen saccade when the threshold is reached in the RT task or when the GO signal is given in the variable delay period in the FD task. (In both left and right movies, blue refers to LIP cell coding the right choice target and red to that for the left target.) |
DECISION CELLS AND DECISION GATINGFIXED DURATION TASK
|